
티스토리 뷰
[EMNLP 2024] Model Internals-based Answer Attribution for Trustworthy Retrieval-Augmented Generation
공부하는묵 2025. 3. 26. 23:291. Introduction
- RAG를 통해 QA에서의 LLM의 hallucination 문제를 해결할 수 있었음
- RAG는 질의에 대한 검색을 통해 검색한 문서를 LLM에 입력
- 하지만 생성된 응답(Answer)이 검색된 문서(Context)를 통해 생성된 것인지 확인하는 것은 어렵다
- NLI 모델을 통해 검색된 문서를 premise라고 생각하고, 생성된 응답이 entailment hypothesis라고 생각하여 판별할 수도 있으나, 외부 모델을 도입해야 하는 문제 발생
- Self-Citation은 프롬프트를 통해 모델이 생성한 응답에 대한 출처를 명시하도록 하나, 모델이 프롬프트에 있는 instruction을 완전히 따르지는 못함
2. Method
총 3단계로 이루어진다.
1. Context-sensitive Token Identification (CTI): 생성된 answer 토큰 중에 context의 영향을 많이 받은 토큰을 찾는 단계
2. Contextual Cues Imputation (CCI): CTI에서 찾은 토큰이 어떤 context 내 토큰의 영향을 받았는지 찾는 단계
3. From Granular Attributions to Document-level Citations: 1, 2 단계에서 토큰 별 점수를 기반으로 어떤 문서가 응답 생성에 영향을 줬는지 계산하는 단계

2.1 Step1: Context-sensitive Token Identification (CTI)
- 생성된 answer(y) 내의 각 토큰의 확률 분포를 프롬프트에 context가 포함된 경우/포함되지 않은 경우를 비교
- KL divergence를 통해 확률 분포의 차이를 비교
- KL divergence 가 특정 기준 이상이라면 context에 영향을 많이 받은 토큰 (기준에 대해서는 이후 서술)

2.2 Step2: Contextual Cues Imputation
- LLM에 y를 넣어 얻을 수 있는 분포와 context를 제외한 y\c를 넣어서 얻는 분포 활용
- 각 context 토큰에 대해 y, y\c를 통해 얻는 확률 차이를 이용
- 확률 차이에 각 토큰 임베딩의 그레디언트를 취하여 각 context 토큰이 얼마나 많은 영향을 끼쳤는지 계산(aij)
- aij에서 특정 기준 이상이라면 answer에 영향을 많이 준 context 토큰
- 결과적으로는 각 answer 토큰(y)과 answer 토큰에 영향을 많이 준 context 토큰(c)의 쌍이 나오게 됨



2.3 From Granular Attributions to Doument-level Citations
CTI Filtering
CTI에서 KL divergenve 값에 대한 threshold 지정 방식
calibrated threshold: human annotation을 이용하여 threshold 지정
example-level threshold: 평균과 분산값을 이용하여 threshold 지정
CCI Filtering
aij 값의 상위 top-k 퍼센트 값을 threshold로 지정
Sentence-level Aggregation
CTI를 통해 얻은 context 영향 받은 answer 토큰 중에서
CCI를 통해 영향을 많이 준 context 토큰이 식별 된 경우 그 토큰이 속한 documet는 영향을 준 context이다.
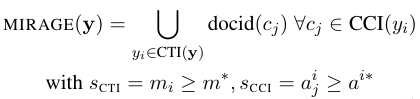
3. Experiments
3.1 Dataset
XOR-AttriQA 데이터셋
query, 관련 context, T5를 통해 생성된 한 문장의 응답. multilingual
human annotator를 통해 어떤 document가 응답에 영향을 줬는지 라벨링 (calibrated threshold 사용을 위해)
ELI5 데이터셋
구성은 비슷하지만 응답이 여러 문장으로 이루어져 있음
TRUE 모델을 통해 어떤 document가 응답에 영향을 줬는지 라벨링
3.2 Results (XOR-AttriQA)

- 외부 모듈의 사용 없이도 높은 성능 달성
- 또한 사용하는 언어가 달라저도 robust한 성능을 보였다
3.3 Results (ELI5)

- 제안 방법은 더 긴 context에 대해서도 잘 작동
3.4 Average Performance on ELI5 answer sentences binned by length

- example level threshold는 생성된 응답의 품질에 많은 영향을 받는다
- 실제로 생성된 응답이 짧을 경우 낮은 성능을 보였음
- 하지만 이는 self-citation도 비슷한 양상이었다
- 추가 연구 필요
'논문 리뷰' 카테고리의 다른 글
- Total
- Today
- Yesterday
- #BOJ #알고리즘 #1034번
- LeetCode
- javascript
- llm agent
- 인과관계추론
- Rag
- LLM
- 베르누이분포
- #BOJ #그리디알고리즘
- #브루트포스
- directives
- 조건부확률
- DECI
- #information_retrieval
- NAACL21
- #BOJ
- GCN
- CoT
- 파이토치
- two-pointers
- #BOJ #2467번 #투포인터알고리즘
- emnlp2024
- python
- #BOJ #유클리드호제법
- KL_Divergence
- #1405번
- PyTorch
- sliding window
- emnlp
- iclr
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |